
Hãy đi thẳng vào vấn đề. Tài liệu nội bộ về API Kho Nội Dung của Google Search đã bị rò rỉ. Các dịch vụ vi mô nội bộ của Google dường như phản ánh những gì Google Cloud Platform cung cấp và phiên bản nội bộ của tài liệu cho Kho Document AI đã ngừng hoạt động bị công khai nhầm lên một kho mã nguồn của thư viện khách hàng. Tài liệu cho mã này cũng bị một dịch vụ tài liệu tự động bên ngoài ghi lại.
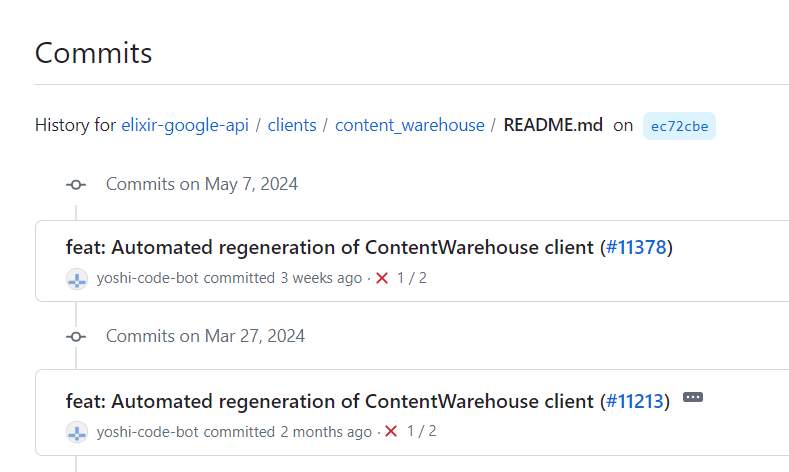
Dựa trên lịch sử thay đổi, lỗi kho mã nguồn này đã được sửa vào ngày 7 tháng 5, nhưng tài liệu tự động vẫn đang trực tuyến. Trong nỗ lực hạn chế trách nhiệm tiềm tàng, tôi sẽ không liên kết đến nó ở đây, nhưng vì tất cả mã trong kho đó được xuất bản theo giấy phép Apache 2.0, bất kỳ ai bắt gặp nó đều được cấp một bộ quyền rộng rãi, bao gồm khả năng sử dụng, chỉnh sửa và phân phối nó theo bất kỳ cách nào.
Tôi đã xem xét tài liệu tham khảo API và đặt nó vào bối cảnh với một số rò rỉ trước đó của Google và lời khai chống độc quyền của DOJ. Tôi kết hợp điều đó với nghiên cứu bằng sáng chế và bài báo sâu rộng cho cuốn sách sắp ra mắt của tôi, “Khoa học SEO”. Mặc dù không có chi tiết về các hàm tính điểm của Google trong tài liệu tôi đã xem xét, nhưng có rất nhiều thông tin về dữ liệu được lưu trữ cho nội dung, liên kết và tương tác của người dùng. Cũng có các mức độ mô tả khác nhau (từ cực kỳ ít ỏi đến đáng ngạc nhiên là tiết lộ) về các tính năng đang được xử lý và lưu trữ.
Bạn có thể bị cám dỗ để gọi chung những thứ này là “các yếu tố xếp hạng,” nhưng điều đó không chính xác. Nhiều, thậm chí hầu hết, trong số chúng là các yếu tố xếp hạng, nhưng nhiều yếu tố thì không. Những gì tôi sẽ làm ở đây là đặt bối cảnh cho một số hệ thống xếp hạng và tính năng thú vị nhất (ít nhất là những thứ tôi có thể tìm thấy trong vài giờ đầu tiên khi xem xét rò rỉ lớn này) dựa trên nghiên cứu sâu rộng của tôi và những điều Google đã nói/ nói dối với chúng ta trong nhiều năm qua.
“Nói dối” nghe có vẻ nặng nề, nhưng đó là từ chính xác nhất để sử dụng ở đây. Mặc dù tôi không nhất thiết đổ lỗi cho các đại diện công khai của Google vì bảo vệ thông tin sở hữu trí tuệ của họ, nhưng tôi phản đối việc họ cố gắng làm mất uy tín của những người trong lĩnh vực tiếp thị, công nghệ và báo chí đã đưa ra những khám phá có thể tái tạo. Lời khuyên của tôi cho những nhân viên tương lai của Google khi nói về những chủ đề này: Đôi khi tốt hơn là chỉ nên nói “chúng tôi không thể nói về điều đó.” Sự tín nhiệm của bạn rất quan trọng, và khi những rò rỉ như thế này và lời khai như trong phiên tòa DOJ xuất hiện, việc tin tưởng vào những tuyên bố trong tương lai của bạn trở nên không thể.
NHỮNG ĐIỀU CẦN LƯU Ý
Tôi nghĩ rằng tất cả chúng ta đều biết mọi người sẽ cố gắng làm mất uy tín các phát hiện và phân tích của tôi từ lần rò rỉ này. Một số người sẽ đặt câu hỏi tại sao điều này quan trọng và nói “nhưng chúng ta đã biết điều đó rồi.” Vì vậy, hãy để tôi giải quyết những điều cần lưu ý trước khi chúng ta đến với những thông tin thú vị.
Thời Gian và Ngữ Cảnh Hạn Chế
Với kỳ nghỉ cuối tuần, tôi chỉ có thể dành khoảng 12 giờ tập trung cao độ vào tất cả những điều này. Tôi vô cùng biết ơn một số người ẩn danh đã rất hữu ích trong việc chia sẻ những hiểu biết của họ với tôi để giúp tôi nắm bắt nhanh chóng. Cũng giống như lần rò rỉ của Yandex mà tôi đã đề cập năm ngoái, tôi không có cái nhìn toàn diện. Trong trường hợp của Yandex, chúng tôi có mã nguồn để phân tích mà không có suy nghĩ đằng sau nó, còn trong trường hợp này, chúng tôi có một số suy nghĩ đằng sau hàng ngàn tính năng và mô-đun, nhưng không có mã nguồn. Bạn sẽ phải thông cảm cho tôi vì chia sẻ điều này một cách ít có cấu trúc hơn so với những gì tôi sẽ làm trong vài tuần tới sau khi tôi đã nghiên cứu kỹ hơn về tài liệu này.
Không Có Các Hàm Tính Điểm
Chúng tôi không biết cách các tính năng được cân nhắc trong các hàm tính điểm khác nhau. Chúng tôi không biết liệu mọi thứ có sẵn có đang được sử dụng hay không. Chúng tôi biết rằng một số tính năng đã bị ngừng sử dụng. Trừ khi được chỉ rõ, chúng tôi không biết cách các yếu tố này đang được sử dụng. Chúng tôi không biết mọi thứ xảy ra ở đâu trong quy trình. Chúng tôi có một loạt các hệ thống xếp hạng được đặt tên mà sơ bộ phù hợp với cách Google đã giải thích chúng, cách các chuyên gia SEO đã quan sát thứ hạng trong thực tế, và cách các ứng dụng bằng sáng chế và tài liệu IR giải thích. Cuối cùng, nhờ vào lần rò rỉ này, chúng tôi giờ đây có cái nhìn rõ ràng hơn về những gì đang được xem xét, từ đó có thể định hướng những gì chúng ta nên tập trung vào hoặc bỏ qua trong SEO trong tương lai.
Có Thể Là Bài Đầu Tiên Trong Nhiều Bài
Bài viết này sẽ là cú đột phá ban đầu của tôi về những gì tôi đã xem xét. Tôi có thể sẽ đăng các bài viết tiếp theo khi tôi tiếp tục đi sâu vào các chi tiết. Tôi nghi ngờ rằng bài viết này sẽ dẫn đến việc cộng đồng SEO đổ xô vào phân tích các tài liệu này và chúng ta sẽ cùng nhau khám phá và tái cấu trúc lại các thông tin trong nhiều tháng tới.
Đây Dường Như Là Thông Tin Hiện Hành
Theo như tôi có thể biết, lần rò rỉ này đại diện cho kiến trúc hiện tại, đang hoạt động của Kho Lưu Trữ Nội Dung Tìm Kiếm của Google tính đến tháng 3 năm 2024. (Dự đoán một nhân viên PR của Google sẽ nói rằng tôi sai. Thực tế thì chúng ta hãy bỏ qua phần trình diễn này đi.) Dựa trên lịch sử cam kết, mã liên quan được đẩy lên vào ngày 27 tháng 3 năm 2024 và không bị gỡ bỏ cho đến ngày 7 tháng 5 năm 2024.